|
|
 |
|
|
|
Wolfgang Marks: Die Formatierte DNA
|
|
|
Chromatin-Domänen sind formatting units.
Chromatin-Subdomänen die zentralen Funktionseinheiten des Genoms.
Jede Chromatin-Domäne des Genoms stellt eine formatting unit dar einen DNA-Abschnitt, der in einer definierten Zelle in allen Phasen des Zellzyklus eine einheitliche, distinkte Formatierung aufweist. Da die Formatierung mit einer bestimmmten Nukleosomengrösse wie ich später noch zeigen werde -die Auswahl des Promotors und anderer Faktoren bestimmt, welche die differentielle Genexpression steuern, kommen der Chromatin-Domäne und ihren Subdomänen Schlüsselfunktionen in der Ontogenese zu.
Die Formatierung einer Chromatin-Domäne muss natürlich einen Ursprung haben es muss also zum einen Regionen geben, an welche die zuvor beschriebenen remodeling-Maschinen binden, zum anderen einen definierten Punkt, ein Basenpaar oder ein Nukleotid, das den ersten Kontakt mit einem Histon des Oktamers herstellt, also die Position des ersten Oktamers der durch die Nukleosomengröße (das spacing) definierten Nukleosomenkette oder reihe festlegt.
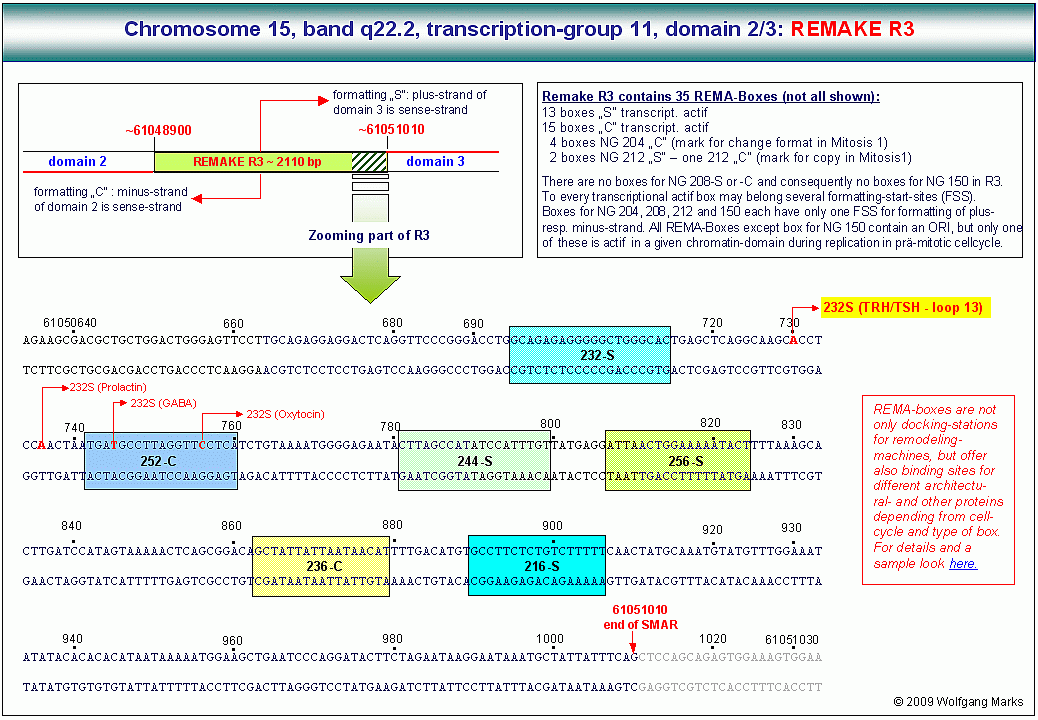
Am Beginn einer jeden Chromatin-Domäne des Chromosomenbandes 15q22.2 habe ich mittels IMPACD® einen Abschnitt identifiziert, den ich REMAKE97 (REmodeling MAchines-KomplEx ) genannt habe. Ein solcher REMAKE befindet sich am Beginn (bzw. Ende) jeder Chromatin-Domäne.
Jede Chromatin-Domäne beginnt mit einem REMAKE-Komplex.
REMAKEs sind Informationsspeicher und enthalten REMA-Boxen dockingstations für remodeling-Maschinen.
REMAKEs stellen um wiederum einen Begriff aus der EDV zu verwenden eine Art FAT dar also eine Art file allocation table98. Im humanen REMAKE sind zwar keine Datei-Tabellen zu finden und auch keine Hinweise darauf, wo bestimmte Gene gespeichert sind, dafür findet sich aber in ihm die Information, von welchem Startpunkt aus und mit welcher Nukleosomengrösse die dem REMAKE-Komplex jeweils benachbarten Chromatin-Domänen in einer Zelle, die sich differenzieren will, zu formatieren sind.
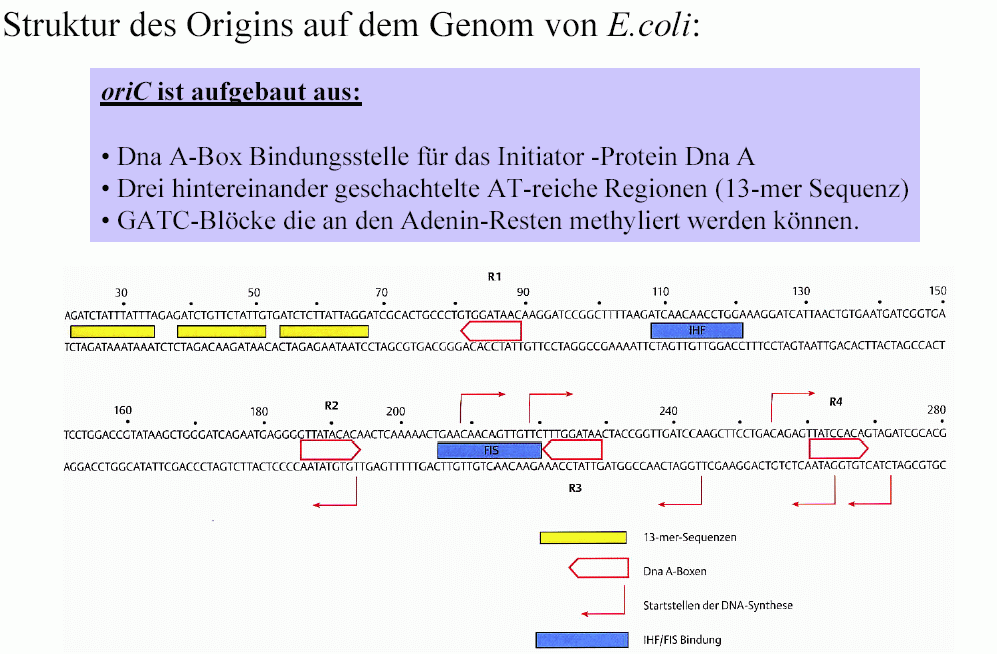
Alle von mir bisher identifizierten und analysierten REMAKEs sind zwischen ca. 1500 und ca. 4500 Basenpaare groß. Sie weisen gewisse Analogien zum OriC von Esch. coli auf. Denn es gibt in ihnen offensichtlich Sequenzen, die Ähnlichkeit mit den Dna-A-Boxen von Esch. coli haben und nach dem Ergebnis meiner Berechnungen Bindestellen für die zuvor beschriebenen remodeling-Maschinen darstellen. Diese Sequenzen, diese Bindestellen habe ich deshalb REMA-Boxen genannt.
|
|
|
|
|
|
|
|
Das Gen für ein metabolisches Protein kann sowohl auf dem plus- als auch auf dem minus-Strang liegen. Während bei Bakterien bei Escherichia coli zum Beispiel die Transkriptionsrichtung auf dem gleichen Strang von Gen zu Gen variieren kann, ist in einer eukariotischen Zelle die Transkriptionsrichtung für alle metabolischen Gene eines DNA-Stranges in einer bestimmten Domäne und in einem bestimmten DNA-Abschnitt einheitlich. Expression und Regulation eines metabolischen Gens müssen deshalb auch mit einer Formatierung des DNA-Doppelstrangs verbunden sein, die mit der Position der essentiellen transkriptionsaktivierenden und regulierenden Sequenzen (vor allem von Promotoren, Transkriptionsstartstellen und poly-A-Signalen) dieses Gens derart korreliert ist, dass diese nach der Formatierung sämtlich auf der linker-DNA des Zielstrangs liegen. Dementsprechend muss es auch wie bereits ausgeführt - remodeling-Maschinen für die Aktivierung von Genen auf dem plus-Strang99 geben von mir remodeling-Maschinen S genannt - und von solchen auf dem minus-Strang von mir als remodeling-Maschinen C bezeichnet.
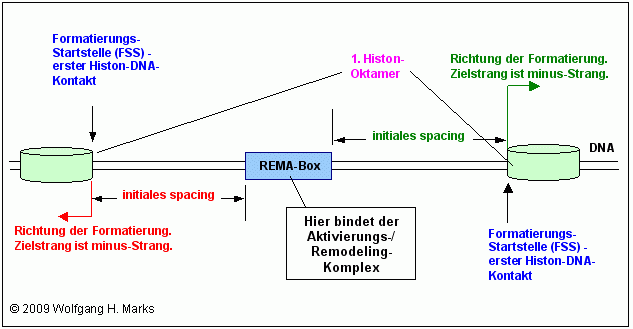
Für beide Arten von remodeling-Maschinen gibt es folglich auch jeweils REMA-Boxen, an welche die remodeling-Maschinen aber mit großer Wahrscheinlichkeit nicht direkt und unmittelbar binden, sondern mit Hilfe und unter Vermittlung eines Aktivierungskomplexes, der in Verbindung mit der remodeling-Maschine die Startstelle und damit die Richtung und den Zielstrang der Formatierung bestimmt. Die Formatierungs-Startstelle von mir mit FSS abgekürzt markiert denjenigen Punkt auf der DNA, an dem es zum ersten Kontakt zwischen der DNA und einem Histon-Protein kommt. Von diesem Punkt aus werden die stromab (plus-Strang ist sense-Strang) bzw. stromauf (minus-Strang ist sense-Strang) folgenden Histon-Oktamere Zug um Zug durch einen für das Chromosomenband spezifischen remodeling-Komplex100 modifiziert und auf der DNA in gleichen Abständen in Phase - positioniert.
REMA-Boxen sind etwa 15 bis 23 bp groß.
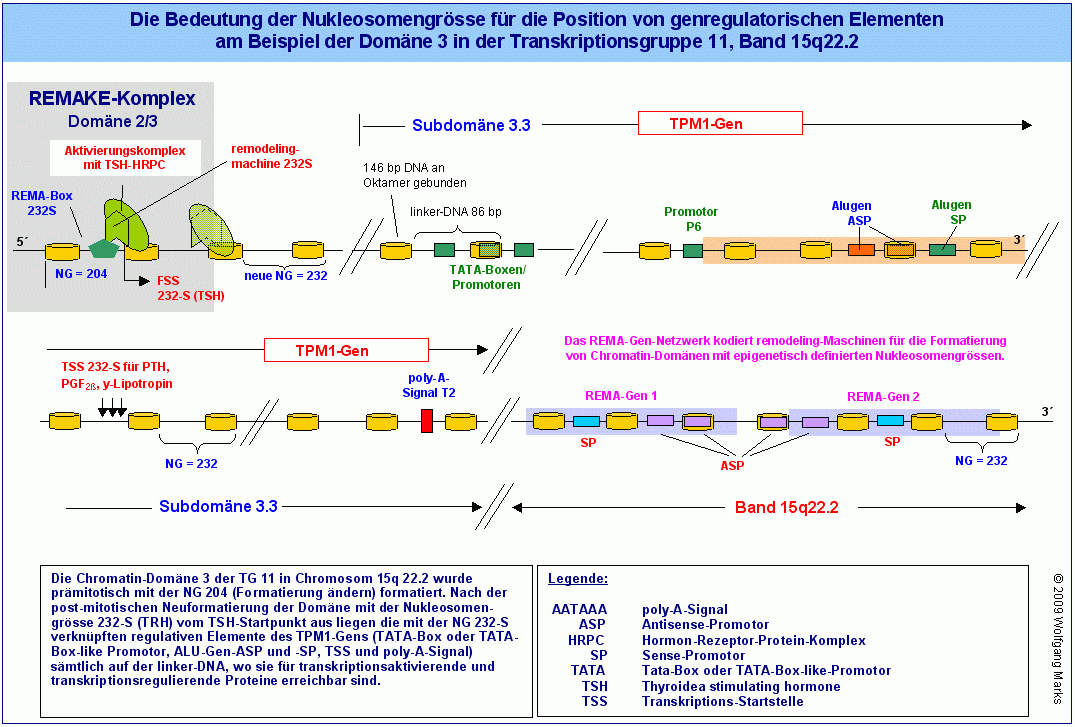
Der in einem Ausschnitt gezeigte REMAKE R3 enthält 13 solcher REMA-Boxen S für die Formatierung der Chromatin-Domäne 3 (sense-Strang = plus-Strang) und 15 REMA-Boxen C (jeweils nur ein Teil gezeigt) für die Formatierung der Domäne 2 (sense-Strang = minus-Strang ) mit transkriptionsaktiven Nukleosomengrössen. Dazu kommen 4 Boxen für das Format 204 (Markierung für Format ändern) und 3 Boxen für das Format 212 (Markierung für Format kopieren). Der REMAKE R3 enthält keine Boxen für das Format 208 S oder 208 C (Markierung für Domäne stillegen) und deshalb auch keine Box für die Nukleosomengrösse 150. Das bedeutet, dass sowohl in der Domäne 2 als auch in der Domäne 3 während der Ontogenese keine Gene stillgelegt werden. In anderen REMAKEs aber gibt es solche Boxen natürlich so zum Beispiel im benachbarten REMAKE R2.
Zu jeder transkriptionsaktiven Box also ausser denen für die Markierungsgrössen 204-S und 204-C, 208-S und 208-C sowie 212-S und 212-C und natürlich 150 S und C - gehören mehrere Formatierungs-Startstellen, die jeweils durch einen Protein-Komplex definiert werden, in dem sich unter anderem aktivierte Aggregate aus einer Rezeptorprotein-Untereinheit und einem primären Transkriptionshormon befinden. Diese Formatierungs-Startstellen liegen ca. 8 bis 70 Basenpaare stromauf bzw. stromab der jeweiligen Rema-Box auf dem Formatierungs-Zielstrang. Sie definieren wie bereits erwähnt - den ersten Histon-DNA-Kontakt also die Position des ersten Histon-Oktamers in der Chromatin-Domäne unter Berücksichtigung des Zielstrangs.
Allein zu den 15 transkriptionsaktiven REMA-Boxen für remodeling-Maschinen S also für die Formatierung des plus-Strangs der Domäne 3 - gehören ca. 50 Formatierungs-Startstellen101für die Formatierung dieser Domäne mit jeweils einer von 19 möglichen transkriptionsaktiven Nukleosomengrössen. Alle FSS ausser der für die Nukleosomengrössen 208 (Markierung für Stillegung) und 150 (stillegen) - werden durch ein Protein-Aggregat lokalisiert, in dem sich unter anderem ein aktivierter Komplex aus einer Rezeptorprotein-Untereinheit und einem primären Transkriptionshormon befindet. Die Zahl der zu einer bestimmten transkriptionsrelevanten Box gehörenden FSS entspricht deshalb der Zahl der primären Transkriptionshormone, die durch das übergeordnete Formatierungshormon aktiviert an der Regulierung der Expression der Gene in der jeweiligen Domäne beteiligt sind. Die Details dieses Prozesses werde ich in Teil III besprechen.
|
|
|
|
|
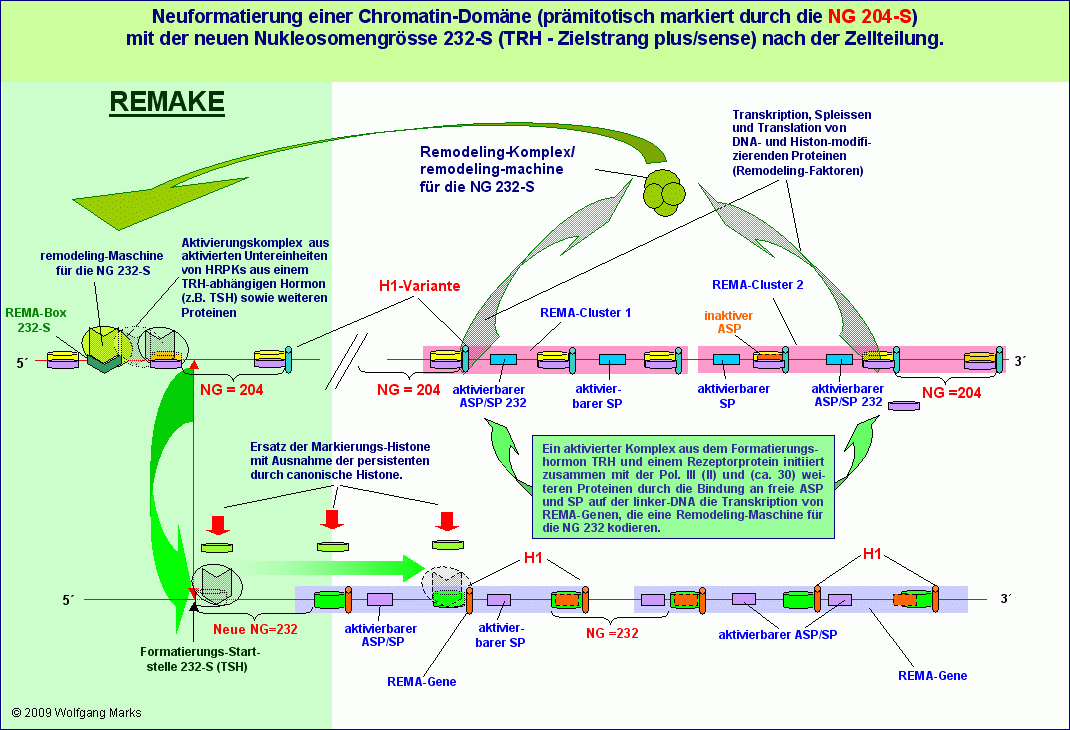
Ein Beispiel: Ist das aktivierende Formatierungshormon das sogenannte Releasinghormon TRH, so befindet sich im Aktivierungskomplex ein aktiviertes Aggregat aus einem von TRH abhängigen primären Transkriptionshormon (zum Beispiel TSH oder Oxytozin) und einem Rezeptorprotein für dieses primäre Transkriptionshormon. Dieser Aktivierungskomplex bestimmt in Verbindung mit der spezifischen remodeling-Maschine (RM) Startpunkt und Richtung der Formatierung das Aggregat aus RM und Aktivierungskomplex legt also fest, welche der beiden dem REMAKE anliegenden Domänen mit der aktuellen Nukleosomengrösse die dem übergeordneten Formatierungshormon entspricht - formatiert wird.
Zu jeder REMA-Box können mehrere Formatierungs-Startstellen gehören.
Es gibt demnach für jede transkriptionsaktive Remodeling-Maschine S oder C zwar nur eine REMA-Box, aber abhängig vom aktivierten primären Transkriptionshormon und vom Aktivierungskomplex mehrere Startstellen für die Formatierung des Zielstrangs mit einer definierten Nukleosomengrösse, von der aber in einer bestimmten Zelle nur jeweils eine genutzt wird.
Während die Aktivierung der REMA-Gene selbst (siehe Kapitel REMA-Gene) und damit die Generierung einer bestimmten transkriptionsaktiven Remodeling-Maschine also von der Anwesenheit eines der 19 zuvor definierten Formatierungshormone abhängig ist, ist die zellspezifische Formatierung einer korrelierten Domäne und die Definition der Formatierungs-Startstelle im konnektierten REMAKE zwar nicht allein, aber doch entscheidend von einem Hormon bestimmt, dessen Synthese von eben diesem Formatierungshormon initiiert wird.
So gibt es für die NG 232-S (TRH) im analysierten und gezeigten REMAKE R3 zwar nur eine REMA-Box, aber wahrscheinlich sechs verschiedene Startstellen für jeweils ein TRH-abhängiges primäres Transkriptionshormon. Von diesen 6 Startstellen für die NG 232-S ist die gezeigte Formatierungs-Startstelle bei bp 61050730 mit dem TRH-abhängigen Hormon TSH verknüpft, die anderen gezeigten Startstellen für die NG 232-S wahrscheinlich mit den ebenfalls von TRH abhängigen Hormonen Oxytozin, Prolaktin und GABA. Wie wir später noch sehen werden, kann man jeder dieser Formatierungs-Startstellen ein bestimmtes Primärtranskript eine hnRNA zuordnen, die unter Mitwirkung weiterer Faktoren (TAFs, sekundäre Transkriptionshormone u.a.) zu einer spezifischen mRNA gespleisst wird.
Die Formatierung einer Chromatin-Domäne mit einer bestimmten transkriptionsaktiven Nukleosomengrösse von einer definierten Startstelle aus ist also nicht nur an ein bestimmtes Formatierungshormon gekoppelt, sondern auch an ein von diesem abhängiges primäres Transkriptionshormon.
Die Bedeutung der Formatierungs-Startstelle und des
Nukleosoms Nummer 1.
Die von mir bis heute berechneten Formatierungs-Startstellen liegen sämtlich 8 bis 70 Basenpaare stromauf bzw. stromab der jeweiligen Box auf dem Formatierungs-Zielstrang. Wie weiter oben beschrieben, definiert der remodeling-Komplex aus RM und Aktivierungsproteinen den ersten Histon-DNA-Kontakt und damit die Position des ersten Oktamers in der Domäne. Wahrscheinlich wandert der remodeling-Komplex von der REMA-Box ausgehend an der DNA entlang, bis er auf ein Histon-Oktamer trifft. Nach Prozessierung und Neuausrichtung dieses ersten Oktamers werden die jeweils stromab folgenden Histon-Oktamere nacheinander modifiziert und auf der DNA in gleichen Abständen in Phase - positioniert.
Die Formatierungs-Startstelle ist für die Formatierung der Domäne und die koordinierte Aktivierung von genregulatorischen Elementen in dieser Domäne die ausschlaggebende Grösse, da die Position des ersten Oktamers bei der Formatierung der DNA mit einer bestimmten Nukleosomengrösse in Phase natürlich auch die Position von Promotoren und anderen genregulatorischen Elementen relativ zum Histon-Oktamer bestimmt und damit darüber entscheidet, ob und wo diese Sequenzen auf der linker DNA liegen oder ob sie an ein Oktamer gebunden sind.
|
|
|
|
|
Die Formatierungs-Startstelle (FSS) legt die Position des ersten Oktamers in der Domäne fest. Wahrscheinlich wandert der remodeling-Komplex von der REMA-Box ausgehend an der DNA entlang, bis er auf ein Histon-Oktamer trifft. Nach Prozessierung und Neuausrichtung dieses ersten Oktamers werden die jeweils stromab folgenden Histon-Oktamere nacheinander modifiziert und auf der DNA in gleichen Abständen in Phase - positioniert.
|
|
|
Die Bedeutung der Nukleosomengrösse für die Position von
genregulatorischen Elementen und für das Primärtranskript.
Die für die Aktivierung und Terminierung der Transkription notwendigen Sequenzen sind nach der Neuformatierung der Domäne mit einer der transkriptionsrelevanten Nukleosomengrössen derart auf der linker DNA positioniert, dass sie für transkriptionsaktivierende, -terminierende und regulierende Faktoren zugänglich sind. Auch die Promotoren (SP und ASP) eines Alu-Gens sind (wie in der Abbildung gezeigt) über die jeweils aktive Nukleosomengrösse mit der Startstelle für die Formatierung verknüpft.102 Durch diese Verknüpfung wird unter anderem erreicht, dass die Transkription eines Strukturgens durch einen bestimmten Promotor aktiviert und durch ein bestimmtes poly-A-Signal beendet werden kann. Durch die Kombination eines definierten Promotors mit einem definierten poly-A-Signal werden letztlich die Exons definiert, die in ein Primärtranskript eingehen und damit auch die messenger-RNAs, die aus einem solchen Primärtranskript prozessiert (gespleisst) werden können.
Ein solcherart definiertes Primärtranskript (die Transkriptionsschleife ich werde darauf noch zurückkommen) wird nach hormonabhängiger Aktivierung von ALU-Gen-Promotoren cotranskriptionell mit Hilfe von Transkriptions- und Processing-Faktoren, die durch Sense- und Antisense-Transkripte eines solcherart definierten ALU-Gens kodiert werden, zu einer messenger-RNA weiterverarbeitet. Diesen Prozess werde ich in Teil III im Kapitel über die Funktion der ALU-Gene noch im Detail beschreiben.
Und nicht zuletzt wird durch die Formatierung mit einer bestimmten FH-korrelierten Nukleosomengrösse erreicht, dass ausgewählte ASP und SP von REMA-Genen auf der linker-DNA positioniert werden, wo sie - wie zuvor beschrieben - als stille Promotoren beim Eintreffen eines Differenzierungssignals durch einen Komplex aus einem Formatierungshormon und anderen Proteinen aktiviert werden können.
|
|
|
|
|
Was haben REMAKE und REMA-Box mit der Organisation der DNA in funktionelle Abschnitte und mit dem Origin Of Replication (ORI) zu tun?
Man weiß bereits seit geraumer Zeit, dass die Sequenzeigenschaften eukariontischer Replikationsursprünge zum Teil mit denen von SMAR-Elementen (jeder REMAKE ist zugleich eine SMAR) übereinstimmen. Sowohl in Drosophila als auch beim DHFR-Locus des Hamsters konnte nachgewiesen werden, dass ORIs und SMAR-Elemente kolokalisiert sind (Amati und Gasser, 1990; Dijkwel und Hamlin, 1995). Die Arbeit von Maria A. Lagarkova et al.103 konnte 1998 weitere Belege dafür erbringen, dass ORIs mit SMAR-Elementen assoziiert sind:
(Zitat): The recently developed procedure of topoisomerase II-mediated DNA loop excision has been used to analyze the topological organization of a human genome fragment containing the gene encoding lamin B2 and the ppv1 gene. A 3.5 kb long DNA loop anchorage/topoisomerase II cleavage region was found within the area under study. This region includes the end of the lamin B2 coding unit and an intergenic region where an origin of DNA replication was previously found. These observations further corroborate the hypothesis that DNA replication origins are located at or close to DNA loop anchorage regions. (Zitat Ende)
Wenn die von mir als Chromatin-Domänen definierten DNA-Abschnitte tatsächlich Formatierungseinheiten sind, dann ist es logisch anzunehmen, dass sie auch gemeinsam replizierte Einheiten darstellen. Da bei der Replikation der DNA auch die Nukleosomen-konfiguration der Mutterzelle an die Tochterzelle(n) weitergegeben wird, ist es ebenso logisch anzunehmen, dass dieser Prozess seinen Anfang in jeweils der spezifischen REMA-Box nimmt, die mit der aktuellen Ausgangsgrösse korreliert ist. Innerhalb jeder REMA-Box - ausser der für die NG 150 - muss es dann auch einen origin of replication geben, also eine Sequenz, an die der Origin-Recognition-Complex (ORC) bindet.
Sowohl die Proliferation einer Zelle als auch ihre Differenzierung erfordern eine Replikation der DNA. Während die proliferative Teilung (einer ausdifferenzierten Zelle) durchaus in einer Mitose bewältigt werden kann, benötigt die Differenzierung einer Zelle aus Gründen, auf die ich am Schluss dieses Teils II detailliert eingehe, mit großer Wahrscheinlichkeit zwei Zellzyklen, von denen der zweite (ohne S-Phase) nicht vollständig durchlaufen wird, sondern nach Vollendung einer remodeling-Phase sofort in die Arbeitsphase übergeht. Dementsprechend wird auch die DNA nicht ein zweites Mal repliziert und die Vorgänge während des ersten Zellzyklus unterscheiden sich wesentlich von denen des zweiten Zellzyklus nach der Teilung der Zelle.
Während für die Vorgänge bei der Replikation der DNA und der Rekonstitution des Chromatins in einer proliferierenden Zelle gute Modellvorstellungen entwickelt wurden, liegen die analogen Prozesse bei einer differentiellen Mitose noch weitgehend im Dunkeln. Da ich auf die Vorgänge bei der Differenzierung einer Zelle in zwei Zellzyklen weiter unten noch zurückkomme, sei an dieser Stelle nur gesagt, dass die REMA-Boxen in eukariotischen Zellen zugleich auch Bindestellen für eine Reihe von Proteinen offerieren, die in verschiedenster Form an der Strukturierung, Kondensation und Dekondensation des Chromatins und damit auch an der Aktivierung und Deaktivierung von Chromatin-Domänen und Genen beteiligt sind.
Dass Proteine der SATB-Familie zum Beispiel eine wichtige Funktion bei der Regulation der Replikation der Säuger-DNA haben, wurde verschiedentlich schon vermutet. Die von mir weiter unten aufgezeigte Beziehung dieses Proteins zum Origin of Replication bietet eine einleuchtende Erklärung für den vermuteten Zusammenhang.
|
|
|
97Man verzeihe mir den Mix aus deutschen und englischen Begriffen, aber ich konnte der Versuchung nicht widerstehen, diese Region remake (neu machen) zu nennen.
98Dateizuordnungstabelle
99Das heißt: sense-Strang ist der plus- respektive der minus-Strang in der Folge Zielstrang genannt.
100Es kann in einem bestimmten Chromosomenband immer nur eine remodeling-Maschine S und C für eine bestimmte Nukleosomengrösse geben.
101Die genannten Zahlen für Startstellen und REMA-Boxen sollten unter dem Aspekt betrachtet werden, dass sie sich auf die Entwicklung des gesamten Zellsystems während der Ontogenese beziehen. Auf eine einzelne Zelle und einen bestimmten Zeitpunkt bezogen ist eine bestimmte Chromatin-Domäne natürlich immer nur mit einer einzigen Nukleosomengrösse von einem einzigen Startpunkt aus formatiert.
102Die hier lediglich schematisch dargestellten Zusammenhänge zwischen der FSS, TSS, ALU-Gen-ASP/SP und der Position von aktiven Promotoren und poly-A-Signalen werde ich in Teil III mit konkreten Zahlen und Daten belegen.
103"DNA loop anchorage region colocalizes with the replication origin located downstream to the human gene encoding lamin B2" - Maria A. Lagarkova, Ekaterina Svetlova, Mauro Giacca, Arturo Falaschi, Sergey V. Razin - Journal of Cellular Biochemistry; 69:13-18, 1998
|
|
|